
I'm an avid amateur chess player, in the past 10 years I spent an embarrassing amount of my free time at chess.com, playing blitz games. (Mostly 5+0 format.) I was always hyped when I approached a new milestone with my rating, I recall feeling immense enthusiasm upon hitting 1500. This feeling was replicated a number of times over the years, most recently hitting the 2000 barrier, a very respectable level when it comes to over-the-board chess ratings. Even chess.com reassures me that I'm doing great and belong to the top 0,6% of players with my current rating of 2023. Astonishing improvement taking into account that I spent most of 2015 between 1300 and 1400! However, I never really understood how it happened, as I barely studied chess consciously apart from a few very short periods. Did my chess wisdom simply improved? Did my brain develop in the right direction as a side effect of my advanced math studies? I need to find the answer.
Alternative measures of chess skill
If you play chess online, you probably use chess.com or lichess.org, and you are probably aware of that you can run computer analysis of your games. These tell you which of your moves were excellent, inaccurate, or outright stupid. Ultimately they even return an overall measure of your play, called accuracy. How is this number computed? For lichess.org, the formula is public, for chess.com, it is proprietary, but both boil down the same idea. The chess engine (usually Stockfish, widely considered to be the top engine) working under the hood evaluates each position over the course of the game, and evaluating a position before and after a move yields an evaluation of the move. Your position was evaluated at 2.3 in your favour, after your move it's -1.2, then it was a "3.5 magnitude bad move". Makes sense, doesn't it? No "good moves" are available in the sense that your evaluation cannot improve as 2.3 essentially means that if you play the best move, the evaluation remains at 2.3. You can measure how accurate you were in a game by averaging your "move badness".
Being aware of this alternative measure, I can evaluate my development from an alternative point of view: all I need to do is analyze all my games from the past 10 years in terms and plot the evolution of my accuracy.
What are these numbers by the way?
This is a bit of a technical detour, feel free to skip this section if you are more interested in the detective story. Classically (in terms of Stockfish generations, before Stockfish 12), chess engines evaluated positions according to handcrafted features. The unit of evaluation was the centipawn: one pawn was worth 100 centipawns. Other pieces had their value expressed in centipawns as well: a bishop was worth 333 centipawns, a knight 325 centipawns, and so on. Various positional features, such as a rook on an open file, double pawns, etc., were also defined and converted into centipawns. Thousands of lines of C++ code defined these quantities, which were summed up to result in a single evaluation score describing the position. A move's badness was then called the centipawn loss: how much your evaluation dropped due to you inaccuracy.
With Stockfish 12, neural networks (NNUE=Efficiently Updatable Neural Network) entered the picture and eventually the evaluation score lost its hard-coded relationship with explainable statistics. These neural networks essentially evaluate positions in terms of winning probabilities, nevertheless the language of centipawns was preserved for a while. This was left behind with Stockfish 15.1: now the scores displayed by Stockfish truly stand for winning probabilities. (For the technically minded: scores are mapped to winning probabilities by a well-parametrized sigmoid function.) As the Stockfish FAQ puts it:
The evaluation of a position that results from search has traditionally been measured inpawnsorcentipawns(1 pawn = 100 centipawns). A value of 1, implied a 1 pawn advantage. However, with engines being so strong, and the NNUE evaluation being much less tied to material value, a new scheme was needed. The new normalized evaluation is now linked to the probability of winning, with a 1.0 pawn advantage being a 0.5 (that is 50%) win probability. An evaluation of 0.0 means equal chances for a win or a loss, but also nearly 100% chance of a draw.
They also note that these probabilities are derived from the Stockfish playing itself in bullet games (60 seconds + 0.6 s increment per move), probably somewhat distinct from my level. Nevertheless these numbers are some sort of gold standard in evaluation of chess positions, broadcasted during top chess games as a live evaluation bar.
Back to the main storyline: how to get the data?
As I said, at chess.com I can analyze any match of mine. Shamefully, I'm not a premium user so I'm limited to 1 analysis per day. Okay, I will tirelessly analyze my games one by one, and in about 20 years... No, that will not do. I have to resort to doing my own analysis instead, meaning one run locally on my computer. Using the chess.com's API downloading all my matches is quite straightforward, see the code at the end of this post. (Thank you, Google Gemini! Do not scrutinize it harshly, it was written by poor AI, not me.)
In a few minutes I have all data on board. It remains to do the actual analysis.
How to do the analysis locally?
I need to get a chess engine on my own computer. Clearly I'd like to use the best one, Stockfish. What makes it truly the best for my purposes is the fact tha it's completely open source. If you do not want to bother with codes, you can download it as an executable with which Python can interact through its python-chess library. All we have to do is load the engine, load the games, iterate over the moves and evaluate them one-by-one. Code is provided at the end by Google Gemini one more time, just two tiny remarks here about it:
- the analysis has a parameter DEPTH, which is set at a lower-than-usual choice of 12. This means that Stockfish analyzes positions up to 6 pairs of subsequent moves. In top-level chess streams, live evaluation bars use Stockfish with depth 20-24. However, increasing depth massively increases computation time and for the overall analysis of the accuracy of my amateur level blitz games, DEPTH=12 probably does the trick.
- There is a slight confusion between what Stockfish 17.1 actually does and what Google Gemini believes it is doing. Notably, Google Gemini calls the evaluation scores centipawn_loss, while we have seen that the evaluation scores do not represent centipawn loss anymore, it is a piece of outdated knowledge used by Gemini. I do not bother with changing it, I'm fine with the obsolete terminology.
Okay, but what are the results?
The results can be seen on this graph, indicating a steady, but not at all flashy improvement. In reality, I'm not at all disappointed, it feels really nice to see that games played outrageously badly (ACPL>100) almost disappeared as time progressed.
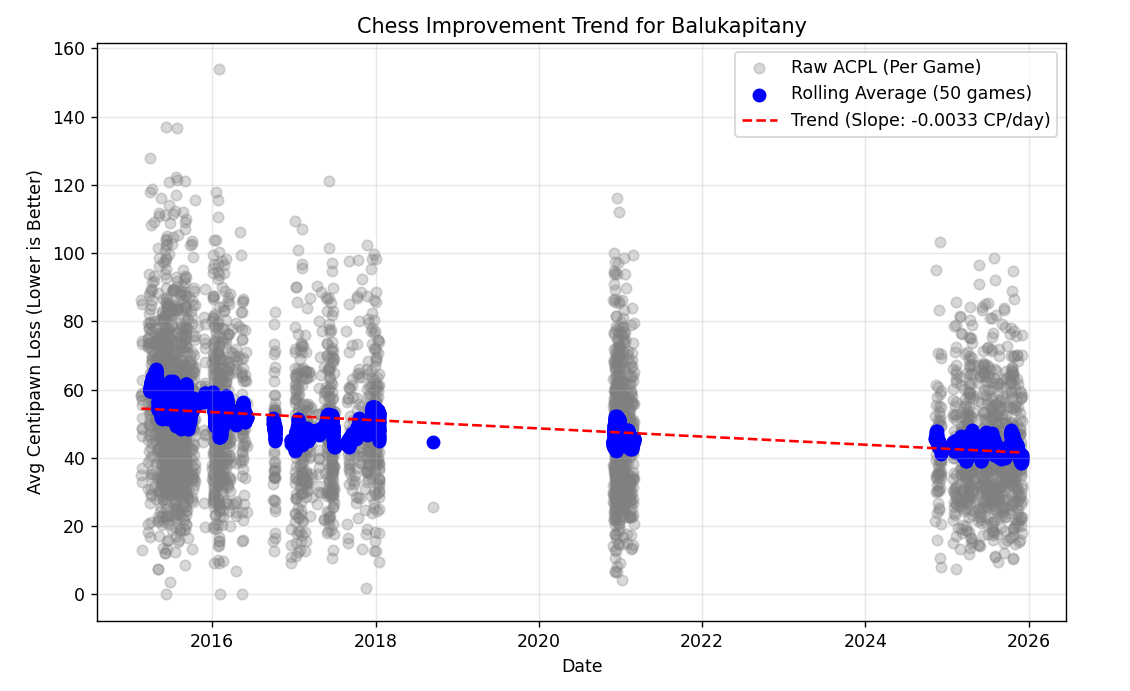
But what about my rating? Let's check it on chess.com
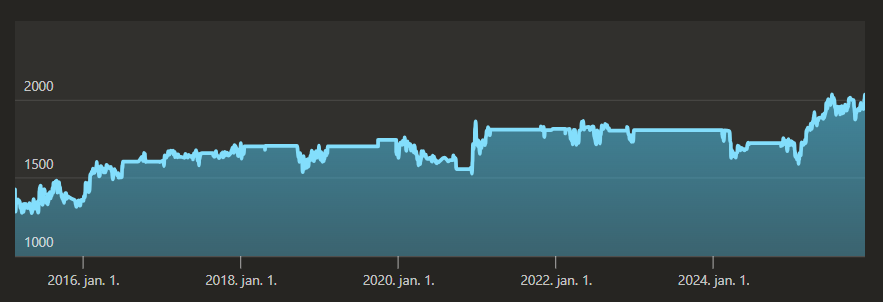
One can see all sort of spikes here, deceiving me to see sudden jumps in my playing ability:
- In the beginning of 2016, a jump from ~1350 to ~1550.
- in 2021 a sudden growth from ~1500 to ~1800
- in my post-2024 playing period another quick growth from ~1600 to ~2000.
Can we read these leaps off from the other chart? Not at all, strongly suggesting that similar performance is worth significantly higher rating then previously. While I improved to some extent, the main driver of my rating was inflation.
Disclaimer
Of course, the results of this analysis should be taken with caveats and not be considered as very categorical statements.
- First of all, it should be noted that the blitz rating of chess.com covers other time formats than 5+0. In certain stages I preferred playing 3+2, this is the reason why my rating changed in periods when the first chart indicates no games at all. However, in these periods there were no abrupt changes in my rating so it does not make much difference for the moral of the story.
- Average move accuracy is a very rough metric of one's playing ability.
- Time management is a very important aspect of blitz games which I know I used to struggle with and I believe improved in. Mismanaging time and the resulting loss of rating is probably not properly reflected in the first chart.
- I believe one develops tendencies for following certain patterns which do pay off at this level, but from a higher-level view they contain unpunished inaccuracies. Learning to perform these inaccuracies quickly and in a paradox way, accurately might result in a growth of rating despite stagnating accuracy. Now that I have the data and tools to analyze it, maybe I will have a deeper dive in how my games evolved beyond average accuracy.
If you think I missed a factor which might contribute significantly, don't hesitate to share it with me!
Why isn't my rating an absolute measure of skill?
The answer is simple: Elo is relative by design. It tracks match outcomes, not objective perfection. This means your rating doesn't just reflect how well you play, but how you compare to the rest of the player pool. As the pool grows and changes, the "value" of 1500 or 2000 shifts. I can even identify certain changes of the pool in my rating chart: as the Netflix series The Queen's Gambit went viral in 2020, lots of beginners flooded online chess platforms, bringing "cheap Elo" to the system to be consumed by stronger players. Look at my rating chart: it also skyrocketed when I started to play again in 2021.
Fluctuations in how Elo compares to absolute skill is a hot topic even in elite GM circles. The takeaway is clear: Elo is great for matchmaking and local comparison of players, but to measure actual skill, you need a distinct, absolute measure. As a sidenote for the AI community: this observation is also relevant in the field of large language models: while LMArena is a great platform for the relative comparison of models in terms of human preference, the growing ratings do not tell much about whether the models actually improve. Such discussion requires absolute measures, such as performance on various benchmarks, such as MMLU for general knowledge or GPQA for expert reasoning.
So what?
Does it bother me that my 2000 rating is partly 'air'? Not really. I’m still playing more accurately than I was in 2015. But I'm happy to be aware that the number on the screen is more generous than it used to be.
Codes
import requests
import time
import os
# --- SETTINGS ---
USERNAME = "balukapitany" # Change this to your Chess.com username
CONTACT_EMAIL = "discreetly@telling.not" # Chess.com asks for this in the User-Agent
OUTPUT_FILE = f"{USERNAME}_all_games.pgn"
# The API requires a clear User-Agent header
headers = {
'User-Agent': f'ChessDataDownloader/1.0 (Contact: {CONTACT_EMAIL})'
}
def download_all_games():
# 1. Get the list of all monthly archive URLs
print(f"Fetching archive list for {USERNAME}...")
archives_url = f"https://api.chess.com/pub/player/{USERNAME}/games/archives"
response = requests.get(archives_url, headers=headers)
if response.status_code != 200:
print(f"Error fetching archives: {response.status_code}")
return
archive_urls = response.json().get('archives', [])
print(f"Found {len(archive_urls)} months of games.")
# 2. Iterate and download PGN for each month
with open(OUTPUT_FILE, "w", encoding="utf-8") as f:
for url in archive_urls:
# We append '/pgn' to the URL to get the raw PGN instead of JSON
pgn_url = f"{url}/pgn"
print(f"Downloading from: {url.split('/')[-2]}/{url.split('/')[-1]}...")
# Be a good citizen: small delay to avoid hitting rate limits
time.sleep(0.5)
pgn_resp = requests.get(pgn_url, headers=headers)
if pgn_resp.status_code == 200:
f.write(pgn_resp.text)
f.write("\n\n") # Spacing between monthly batches
else:
print(f"Failed to download {url}: {pgn_resp.status_code}")
print(f"--- Finished! All games saved to {OUTPUT_FILE} ---")
if __name__ == "__main__":
download_all_games()Download your games from chess.com
import chess
import chess.pgn
import chess.engine
import csv
# --- CONFIGURATION ---
USERNAME = "balukapitany"
PGN_FILE = f"{USERNAME}_verseny.pgn"
STOCKFISH_PATH = "stockfish/stockfish-windows-x86-64-avx2.exe"
OUTPUT_CSV = f"{USERNAME}_chess_progress.csv"
TIME_CONTROL_FILTER = "300" // use only 5 minute = 300 second games
DEPTH = 12
def analyze_games():
try:
engine = chess.engine.SimpleEngine.popen_uci(STOCKFISH_PATH)
except FileNotFoundError:
print("Error: Stockfish binary not found. Check STOCKFISH_PATH.")
return
with open(PGN_FILE, "r", encoding="utf-8") as pgn_file, open(OUTPUT_CSV, "w", newline='', buffering=1) as csvfile:
writer = csv.writer(csvfile)
writer.writerow(["Date", "Opponent", "Result", "MyColor", "ACPL"])
while True:
game = chess.pgn.read_game(pgn_file)
if game is None:
break
variant = game.headers.get("Variant", "Standard")
if variant != "Standard":
print(f"Skipping variant: {variant}")
continue
if game.headers.get("TimeControl") != TIME_CONTROL_FILTER:
continue
# Determine your color
is_white = game.headers.get("White").lower() == USERNAME.lower()
my_color = chess.WHITE if is_white else chess.BLACK
opponent = game.headers.get("Black") if is_white else game.headers.get("White")
board = game.board()
total_centipawn_loss = 0
my_move_count = 0
info = engine.analyse(board, chess.engine.Limit(depth=DEPTH))
prev_eval = info["score"].relative.score(mate_score=10000)
for move in game.mainline_moves():
is_my_turn = board.turn == my_color
board.push(move)
info = engine.analyse(board, chess.engine.Limit(depth=DEPTH))
white_eval = info["score"].white().score(mate_score=10000)
current_eval = white_eval if is_white else -white_eval
if is_my_turn:
loss = prev_eval - current_eval
actual_loss = max(0, min(loss, 400))
total_centipawn_loss += actual_loss
my_move_count += 1
prev_eval = current_eval
acpl = total_centipawn_loss / my_move_count if my_move_count > 0 else 0
writer.writerow([
game_date,
opponent,
game.headers.get("Result"),
"White" if is_white else "Black",
round(acpl, 2)
])
print(f"Finished: {game_date} vs {opponent} | ACPL: {round(acpl, 2)}")
engine.quit()
if __name__ == "__main__":
analyze_games()Evaluating games in pgn format
Member discussion: